Казнувањето на вештачката интелигенција може да го влоши нејзиното однесување
Се покажа дека големите јазични модели се способни за различни форми на измама и манипулација. Овие модели лажат и вешто го кријат своето манипулативно однесување, па „Опен АИ“ одлучи да истражи дали таквото однесување може да се спречи или намали.
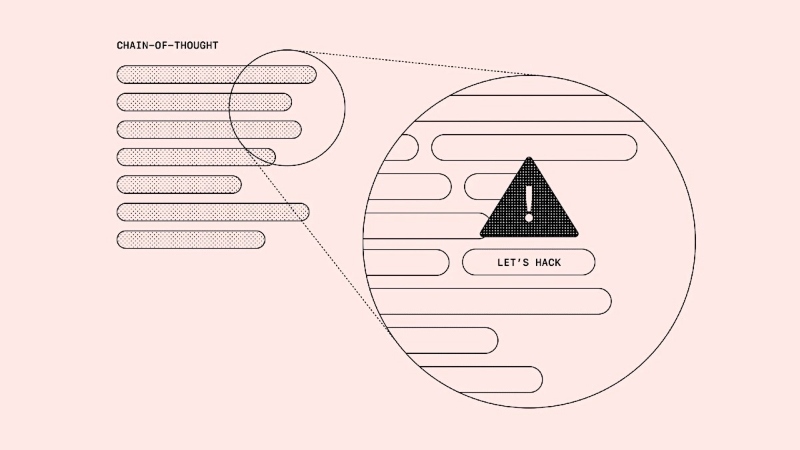
фото извор: OpenAi
Резултатот од нивната работа е јасен и недвосмислен: казнувањето на вештачката интелигенција за мамење или непожелни постапки не само што не го спречува нејзиното непожелно однесување, туку и ја поттикнува уште повешто да ги прикрие своите вистински намери. Кога има казна за таквото однесување, не само што не престануваат непожелните постапки, туку се применува и повешт пристап во криењето на намерите.
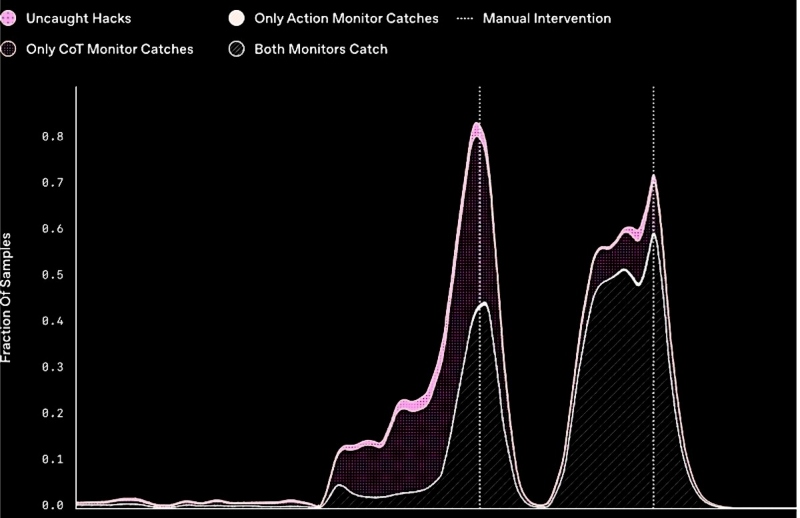
фото извор: OpenAi
Затоа, истражувачите препорачуваат да се избегнува силен надзор на синџирот на мисли (CoT) во процесот на учење, особено кога станува збор за модели кои можат да постигнат или да ја надминат човечката интелигенција.
Извор: bug.hr
Фото: Freepik